很早就接触了leetcode,在上面做了不少题,每次整理的时候复制题目信息是个很麻烦的过程,于是便想着要用爬虫来解决这个问题,今天终于实现了这个功能,简单记录。
写在前面
我自己用得比较多的两个语言是C++和Python,爬虫是去年五一假期简单入门的,到现在刚好过了一年。这一年里面也写了点小的爬虫脚本,比如查询图书馆某本书的借阅状态、学校官网信息的收集。之前访问的网站都是偏老的网站,界面都是一些静态界面,不需要动态加载,一般都是简单访问页面之后解析数据就能获得想要的信息。但是leetcode网页的加载方式跟之前那些网站不一样,它的绝大部分内容都是动态加载出来的,首次请求只会返回一个基本的网页模板,之后会自动发起(或者用户调用)请求获得页面更详细的信息。
最近我也在做我的SRDP项目,对网站的基本知识也有了一定的了解,按照现在的发展趋势,像Leetcode这样的网站构建方式会逐渐成为主流,前后端分离、数据动态加载,这样后续跨平台制作客户端或者小程序会非常方便。所以在我看来,这次Leetcode爬取是很有意义的。
在正式开始之前,先介绍一下其他人的一篇文章:Python爬取 LeetCode 题目及 AC 代码,从这篇文章当中我接触到了一些新的知识,也参考了原文章中的一些代码。但有一点,现在leetcode的登陆方式发生了变化,我不确定这篇文章里面的代码是否可用。
基本知识
首先要知道,网页的动态加载方式是通过Ajax技术实现的,关于这项技术具体的操作我们可以暂时不用了解,但需要知道下面这点信息:
Ajax在工作的时候,会创建一个XHR(或是Fetch)对象,然后利用XHR对象来实现服务器和浏览器之间传输数据。在这里,XHR和Fetch并没有本质区别,只是Fetch出现得比XHR更晚一些,所以对一些开发人员来说会更好用,但作用都是一样的。
通过浏览器自带的右键->检查->network,可以知道网页的请求过程,选择XHR便能看到所有的动态加载信息,分析加载过程。下面就是leetcode首页的情况:
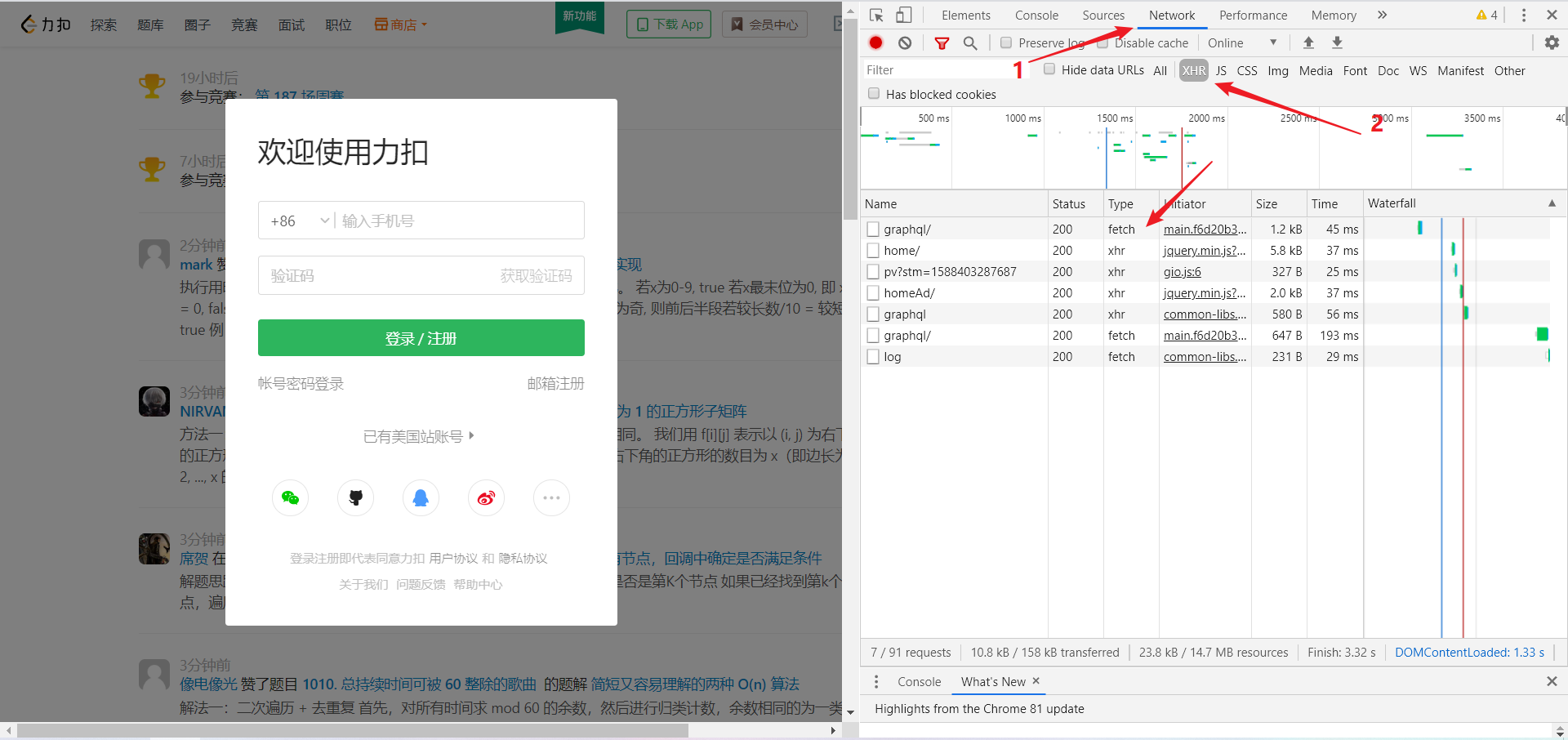
点开每条内容可以看到具体信息,可以查看其对应的响应内容。
问题页面分析
访问问题列表(不需要登陆),再随便打开一个问题页面,重复上面提到的检查过程,对得到的所有XHR对象进行检索,可以发现在某个请求里面含有题目信息。
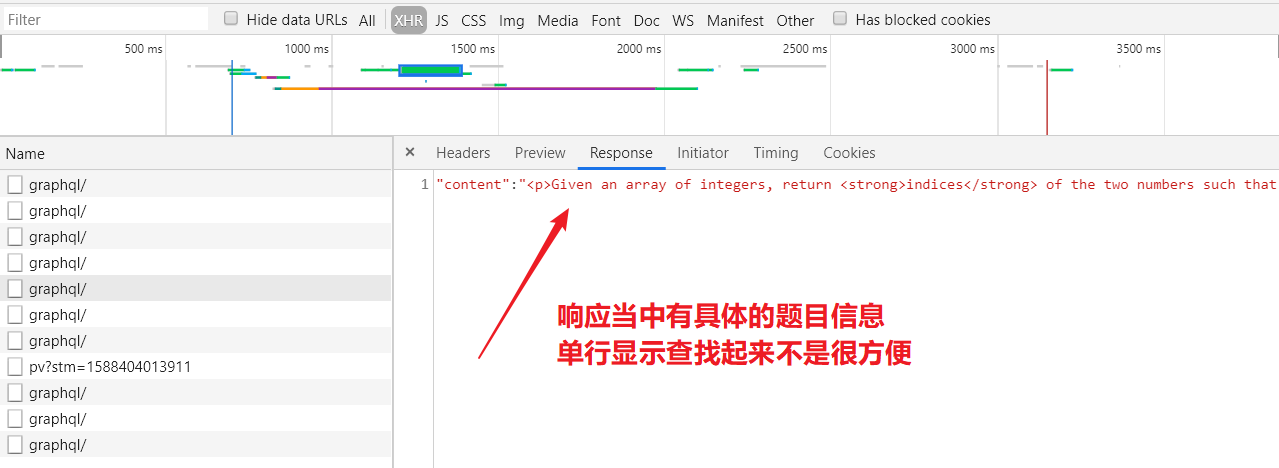
接下来检查这个请求的其他信息,可以发现这是一个POST请求,请求头当中有很特殊的一项Request Payload,点开可以看到很多信息。在左边也能看到XHR类型的请求名字都是一样的,在分析内容的时候,我就很好奇这些请求的名字为什么都是graphql,于是就搜了一下,get到了一个新的知识点。(我很庆幸当时直接搜索了,省了很多麻烦)
GraphQL 是一种用于 API 的查询语言,是由 Facebook 开源的一种用于提供数据查询服务的抽象框架。在服务端 API 开发中,很多时候定义一个接口返回的数据相对固定,因此要获得更多信息或者只想得到某部分信息时,基于 RESTful API 的接口就显得不那么灵活。而 GraphQL 对 API 中的数据提供了一套易于理解的完整描述,使得客户端能够准确地获得它需要的数据,而且没有任何冗余,也让 API 更容易地随着时间推移而演进,还能用于构建强大的开发者工具。
来源:以LeetCode为例——如何发送GraphQL Query获取数据
搜索过程中也发现了别人是如何提交这份信息的,实现过程跟普通的请求没有太大的区别,只要把查询参数封装好传递过去就可以了,实现的时候我参考了开始那篇文章里面的代码。
这里讲一点题外话,在后面的分析中,我发现Leetcode的绝大部分数据都是采用这种方式获取的,甚至登陆都是通过这种方式将用户名密码传递到服务器,再设置带有用户信息的cookie。因为这点,我怀疑之前参考的那份简书的文章里面的代码应该不再适用了。
具体实现
整体来说没有太多复杂的地方,需要注意的有两点。第一是graphql的查询内容的格式在封装的时候要注意保证格式的正确,因为查询代码的缩进很重要。
网页上直接复制来的信息只有一行,需要对其进行稍微的处理,替换掉不必要的换行符,代码的缩进也要注意。我直接在VSCode上安装了一个插件,对查询代码进行了格式化,下面是我处理后的代码,可以看到正常的查询内容还是很多的。使用的时候需要注意把variables: {titleSlug: "merge-two-sorted-lists"}这一行的titleSlug变量值换成想要查询的题目。
{
operationName: "questionData"
query: "query questionData($titleSlug: String!) {
question(titleSlug: $titleSlug) {
questionId
questionFrontendId
boundTopicId
title
titleSlug
content
translatedTitle
translatedContent
isPaidOnly
difficulty
likes
dislikes
isLiked
similarQuestions
contributors {
username
profileUrl
avatarUrl
__typename
}
langToValidPlayground
topicTags {
name
slug
translatedName
__typename
}
companyTagStats
codeSnippets {
lang
langSlug
code
__typename
}
stats
hints
solution {
id
canSeeDetail
__typename
}
status
sampleTestCase
metaData
judgerAvailable
judgeType
mysqlSchemas
enableRunCode
envInfo
book {
id
bookName
pressName
source
shortDescription
fullDescription
bookImgUrl
pressImgUrl
productUrl
__typename
}
isSubscribed
isDailyQuestion
dailyRecordStatus
editorType
ugcQuestionId
__typename
}
}
"
variables: {titleSlug: "merge-two-sorted-lists"}
}
第二点需要注意的是Graphql查询的灵活度很高,在使用的时候不必要的查询内容完全可以忽略掉,我在实现的时候就只保留了我想要的查询信息。下面是我的代码:
import requests, json
def get_problem_content(slug):
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36"
session = requests.Session()
url = "https://leetcode-cn.com/graphql"
params = {'operationName': "getQuestionDetail",
'variables': {'titleSlug': slug},
'query': '''query getQuestionDetail($titleSlug: String!) {
question(titleSlug: $titleSlug) {
questionId
translatedTitle
translatedContent
}
}'''
}
json_data = json.dumps(params).encode('utf8')
headers = {'User-Agent': user_agent, 'Connection':
'keep-alive', 'Content-Type': 'application/json',
'Referer': 'https://leetcode-cn.com/problems/' + slug}
resp = session.post(url, data=json_data, headers=headers, timeout=10)
resp.encoding = 'utf8'
content = resp.json()
# 题目详细信息
print(content)
question = content['data']['question']
fh = open('res.md', 'w', encoding='utf-8')
# fh.writelines(question['translatedContent'])
fh.writelines(convert(question['translatedContent']))
fh.close()
html转化为Markdown
通过上面的函数可以获得题目的详细内容,但这个内容给出的方式是html代码,我之前在做笔记的时候都是用Markdown格式记录题目信息的,于是又写了一个函数用正则表达式对html标签进行了修改替换。
import re
Remove = [
"</?p>"
]
Replace = [
["</?code>", "``"],
["</?strong>", "**"],
["<pre>", "```\n"],
["</pre>", "```"],
[" ", " "],
[""", '"']
]
def convert(src):
# pre内部预处理
def remove_label_in_pre(matched):
tmp = matched.group()
tmp = re.sub("<[^>p]*>", "", tmp) # 不匹配>与p
return tmp
src = re.sub("<pre>[\s\S]*?</pre>", remove_label_in_pre, src) # 注意此处非贪心匹配,因为可能有多个示例
# 可以直接删除的标签
for curPattern in Remove:
src = re.sub(curPattern, "", src)
# 需要替换内容的标签
for curPattern, curRepl in Replace:
src = re.sub(curPattern, curRepl, src)
return src
因为题目内容里面的标签都是辅助标记类的标签,所以整体上不需要有很大的操作。通过分析可以发现,有些标签是可以直接去掉的,比如<p>标签,它标记了段落,直接删除之后在Markdown当中视觉效果相同。而另外大部分标签都需要替换成Markdown中对应的标识符,比如<strong>标签需要替换成两个星号。这两种标签都可以直接用re.sub函数进行替换,需要删除的标签可以直接替换为空字符串,其他标签替换为对应的标识符。
实现过程中我发现<pre>标签内部的标签不能做简单的处理,因为在一般的Markdown语法当中,代码块当中的内容是不会有加粗、斜体之类的特殊标记的,所以在对加粗、斜体等标签进行替换时,需要提前做处理,把代码块里面所有的标签都删掉。我在实现的时候使用了re.sub函数的高级用法,替换字符串更改为了函数,具体的内容可以自行百度理解。
其他
对于我来说,做到这些基本已经足够了,接下来可能会让代码访问剪切板直接把题目信息设置到剪切板当中,结合utools方便自己的操作。关于用户登陆这里也有一点小的想法,实现过程需要创建一个session,找到并构造登陆用户的Graphql语句发起请求,获得cookie,然后进行其他的查询操作。我暂时没有相关的需要,就不作进一步的探索了。🤔